This is feedback after considering A Plan for C++23 Ranges Disclosure: I voted in favor of this. It does not suggest work on views::maybe [P1255R6]. I'm fine with that priority.
Vocabulary is not just Types between Components
There's broad agreement that 'vocabulary types' belong in the standard. Domain independent types that can be used between otherwise uncoupled facilities. They each depend on facilities provided by Standard C++ and can thus be developed independently. Each component can rely on the API of a core vocabulary type not changing. This allows facilities to communicate effectively.
A component can have std::string or std::vector<int> in its interface with little concern. The STL parts of the standard library have always relied on concepts for constraining template parameters implicitly, requiring an Iterator of particular category in places, or specializing algorithms based on such. Composition of container types has also been natural. No one is confused by a std::unordered_map<std::string, std::vector<my::person>>.
The new C++20 range facilities allow composition of algorithms, which means that the names of algorithms will, and must, become part of the vocabulary of C++ programmers. Algorithms, and the names for them, are far broader than the linear containers supported by C++ today. It is a particular problem because C++ has named core algorithms badly, as they were not, until recently, first class entities.
Algorithms are now first class entities
Functions are a terribly overloaded term in C++. Overloaded is an overloaded term.
With respect to ranges and views, however, it should be clear that the adaptors, transformers, and other entities we apply to ranges and views to produce new ranges, views, and values, are now first class entities in their own right.
The important thing, for programmers, is that moving up the ladder of abstraction should not be conceptually more difficult than dealing with existing libraries of functions. We have algorithms that deal with generic types rather than functions that deal with concrete types, but keeping them in mind should not be fundamentally more difficult.
Naming is therefore critical.
As are chosing the algorithms that are primitive, that is, the ones that compose into others in useful ways.
I have some concerns about providing fused algorithms that a sufficiently smart compiler could optimize. On the other hand, I doubt how imminent sufficiently smart compilers are.
Why Haskell keeps coming up
Python was the answer to "Why can't I just write pseudo-code?"
I have text books where the authors seriously discussed writing out your algorithm into pseudo code, and then translating it into actual programming language. Programming languages were too high ceremony to discuss what you wanted to do, while normal English was not structured enough. "Scripting" languages gave precise higher level semantics that were implicit in the pseudo code, or it would have been impossible to translate by hand to other computer languages.
Haskell was designed to do that for algorithm research. The primary goal was to be able to give direct executable form to a research paper. This was early replicable research. The paper provided, on its own, the mechanism to test and reproduce the result. Haskell source code can be embedded in LaTeX and given directly to a Haskell compiler. Every interesting algorithms paper for the last 30 years or so has implicitly included the prelude.
Haskell itself is not a terribly complex language. Much of it is specified as sugar where a form is translated into a more primitive expression, as range for loops are in C++. Its power for researchers is in its inherent laziness, that an expression is not evaluated unless it is required, and its purity, that values are immutable. These properties make it straightforward to reason with and about. The core property of lazy evaluation has forced it to be pure, not allowing side-effects. This has forced it to be exemplary, and evolutionary, in supporting value oriented programming.
These factors are why we end up often looking to Haskell.
Value oriented programming has been an emerging style in modern C++. The new Range facilities embody the style. Being able to crib proveably correct facilities from modern programming language research is a benefit.
There was a long period, in which C++ grew up, that academic research lagged behind the pragmatic craft of programming. This has, in retrospect, not been an unqualified success. Parallelism and concurrency were widely implemented without theoretic underpnnings. We are still trying to put C++'s memory model on firm footing. Many constructs regularly used in the past are now understood to be unsound, in explicable ways. Multi-threading should not be an experimental science.
Object orientation is an area which still does not have satisfying theoretic backing. There are various theories that provide many of the same benefits, allowing abstraction and encapsulation. In OO, however, objects have identity and state, which implies that equational reasoning can fail, as two equivalent object may have distinct identity and then different behavior. Temporal calculus formalisms are still open research.
The manifest success of OO{A,D,P} with limited underlying theory has allowed many practitioners to believe that academic research is irrelevant. To the extent of dismissing rigor. Jokes about the "M-word" are emblematic.
Sidebar: Monads are boring
A monad is a generic type with a few operations, some of which can be expressed in terms of the others, that follow a few fundamental and fairly trivial rules. They allow predictable composition of entities that model monad.
It is not about `then`. Although `then` does tend to fall out.
The interesting thing is that algorithms can be built that take generic types that follow some "Laws", and they will do, something, correctly. For some kinds of generic type, what happens may be surprising, even interesting. The surprises will, however, not break anything. That's the point of the semantic guarantees surrounding the operations.
C++ has philosophically adopted semantics surrounding Concepts. A Concept is entitled to demand behavior and laws in addition to the checkable syntax that can be enforced.
The utility for an algorithm writer is that reasoning can be applied at a much higher level. Even beyond the abstraction that this is a Container, or Range, or View, being able reason about the operations for anything that provides a set of well defined operations means that the algorithm is correct, even if the details when applied to a new kind are obscure.
Iterators provide a way for algorithms to work with many containers. Those same, correct, algorithms should be able to work with things that aren't Iterable, or Containers. It turns out having a named way of converting a Type<Type<Value>> to a Type<Value> opens up many algorithms to broader use. Flattening a vector of vectors into a linear vector is not the only use of a `concat`.
Fold: In Which I Become Cranky About Names
One of the most primitive and yet powerful algorithms is `fold`. Fold takes a binary operation and interposes it between elements in an iterable data type. It replaces the commas {a, b, c, d, …} with `op`, resulting in {a op b op c op d … }
Except that is slightly ambiguous. Is that (a op (b op (c op (d)))) or ((((a) op b) op c) op d)
Right or left evaluation of the terms.
Folding right is strictly more general, at least in the lambda calculus. Left fold can be implemented as a right fold, but not vice-versa.
However, in C++, the normal implementation of folds is not as general as it might be, because C++ is strict in evaluating function arguments. This means that even though a fold whose operation might not need to evaluate one of its arguments in order to return a value, will still do so, because the argument is evaluated before being passed to the operation. This mean, in particular, that we can't simply undo fold by using a `cons` operation, reconstructing the list. The entire, indeterminate and possibly infinite, list must be evaluated even though all that is necesary is the first element.
Left folding is tail recursive, and so can be converted to a loop. This is why it seems natural in C++.
Right fold is not generally tail recursive, although for finite sequences in C++, using reverse iterators, foldr is also a loop.
To make the diagrams below pretty, we assume that foldl over a sequence of T takes a single value of type Z and an op of Z -> T -> Z, while foldr over a sequence of T takes an op of type T -> Z -> Z and a value of type Z. For a left fold, the value is given to the op that takes the first element in the sequence, while for a right fold, it is given to the op that takes the last element in the sequence.

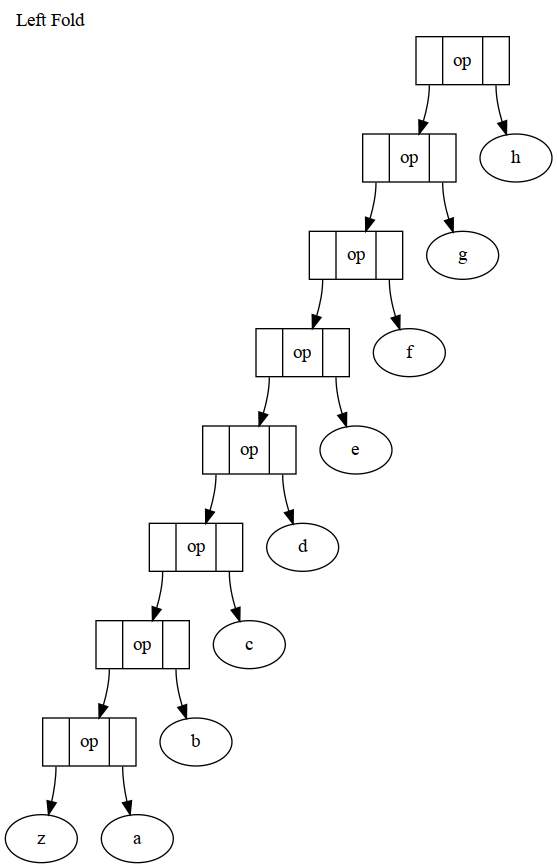
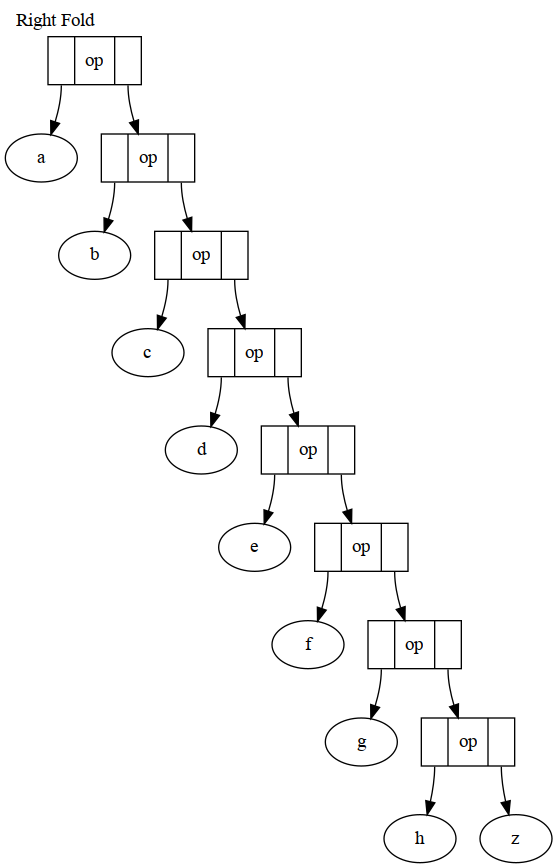 So, left fold piles up the ops on the left and right fold piles them up on the right. The 'zero' or init value is with the last value for a right fold, and the first on a left fold. In converting to iteration, which is important, left fold is in the natural direction, and right fold is reversed, which means it can't be used that way on some sequences.
So which one should be the
So, left fold piles up the ops on the left and right fold piles them up on the right. The 'zero' or init value is with the last value for a right fold, and the first on a left fold. In converting to iteration, which is important, left fold is in the natural direction, and right fold is reversed, which means it can't be used that way on some sequences.
So which one should be the
T fold_left(Range&& r, T init, BinaryOperation op) { range_iterator_t<Range> b = begin(r); range_sentinel_t<Range> e = end(r); for (; b != e; ++b) { init = op(std::move(init), *b); } return init;
auto fold_right_loop(Range&& r, T init, BinaryOperation op) -> result_of<>{ range_iterator_t<Range> b = begin(r); range_sentinel_t<Range> e = end(r); for (; b != e; ++b) { init = op(std::move(init), *b); } return init;
result = op(op(op(op(op(op(op(op(z, a), b), c), d), e), f), g), h);
result = op(a, op(b, op(c, op(d, op(e, op(f, op(g, op(h, z))))))));
fold. It's an important question because short names are implicitly privileged. Programmers assume that the short name is the best one, and longer names indicate more specialized usage. This isn't true for C++, but not really on purpose. We did think that `map` was a good choice. The programmers should probably reach for `unordered_map` instead is unfortunate, but at this point unfixable.
Since C++ is strict, it would seem that left fold is the fold you mostly want, so it would be OK to call it fold.
Haskell, as lazy as it is, has issues with folds on ranges with indeterminate bounds. foldl vs foldr vs foldl' is a constant question. Foldr Foldl Foldl' Memory consumption of either stack or unevaluated expressions will surprise programmers.
But in the literature, fold is right fold. In the pure lambda calculus, right fold is strictly more expressive. Tail recursion is a subset of primitive recursion, and left is tail recursive while right is not. If we call our left fold, fold, we will confuse people.
Further, the forward iteration is somewhat balanced by the fact that the normal addition to a sequence is emplace_back or push_back, which means that left fold will tend to reverse lists if the operation is accumulation into a sequence, if for example the op were [](auto t){v.emplace_back(t);}.
More, we have started to introduce lazy features into the language, with coroutines. Although we won't get them soon, the C++ standard library should eventually have good lazy algorithms. It would be unfortunate if we have to teach that you can't use co_fold in place of fold because they are opposite, or that co_fold_left is how you spell the coroutine fold. [Note co_ prefixes are mildly sarcastic.]
C++ has a long history of setting defaults and realizing later that they are a problem.
I would much prefer we not make a choice about which fold is the fold, and just spell them as fold_left and fold_right.
We should all be able to get behind not calling it accumulate, even if we must live with transform.
Monoid
Some other time I'll vent about the various
fold operations and how they get extended if your type is a monoid. See Chris Di Bella's work such as A Concept Design for the Numeric Algorithms, although this rant suggests that algorithms that operate on different Concepts should have different names. Overloading on concepts with semantic differences can be confusing.